Marlowe Computing Spotlight: Andreas Tolias Lab

The Tolias Lab explores the interface of neuroscience and AI research.
In simple terms, how would you describe the research problem(s) you are trying to solve?
Traditionally, neuroscience has relied on hypothesis-driven approaches: researchers propose a theory about brain function and design specific experiments to test it. Our team is shifting this paradigm by building a foundation model similar in concept to the large language models (LLMs) powering modern AI.
Our goal is to create a model that captures the fundamental principles of how biological brains process visual information. This serves a dual purpose: it acts as a powerful tool for computational neuroscience, and as a source of bio-inspired architectures for more efficient computer vision.
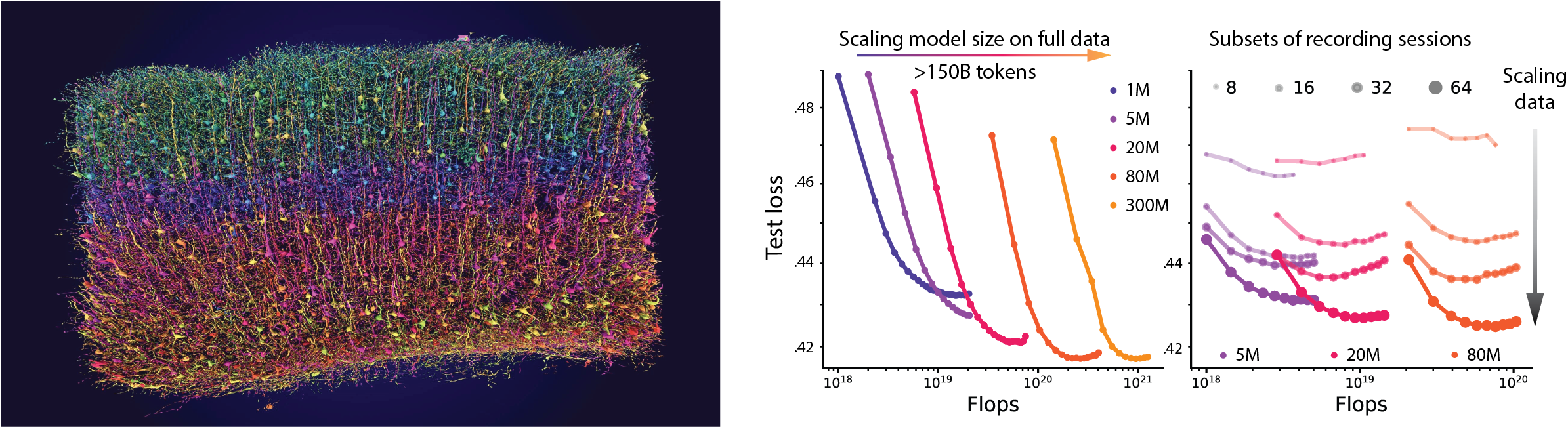
The Enigma Project is developing a large-scale, multi-modal foundation model of the mouse and primate brain. We are training this model on the responses of millions of neurons to natural visual stimuli, leveraging more than 200 billion data points of neural activity data from the MICrONS dataset.
How has Marlowe benefitted your work?
Marlowe has allowed us to scale from initial proofs-of-concept to training multi-billion-parameter models across 128 H100 GPUs. The dedicated compute time provided by Marlowe was essential for these sustained training runs.
Our dataset presents unique challenges compared to standard text training: we utilize neural recordings from more than 300 mice. We capture the activity of neurons in the brain alongside video and behavioral data simultaneously. Marlowe’s high-performance storage enabled us to stream these three data modalities without bottlenecks.
We are also particularly grateful to the NVIDIA Solutions Architects embedded on campus. Zoe Ryan helped us analyze traces and optimize performance throughout development and is organizing lectures through Stanford Data Science on high-performance computing.
Her team’s support allowed throughput comparable to highly optimized language models. Our custom distributed training algorithms even set a new speed record on the nanoGPT benchmark, which is used to test the capabilities of AI coding agents.
What advice would you give other Stanford researchers who might be interested in using Marlowe/HPC?
First, take full advantage of the Marlowe support team and the NVIDIA Solutions Architects on campus; their support was invaluable.
Second, invest time in benchmarking and profiling before scaling up. We dedicated significant development time to identify every possible throughput bottleneck, such as compute, data loading, and inter-node communication.
For our specific workload, data loading remained the primary bottleneck. Because we optimized our architecture and dataloaders prior to moving to multi-node training, we were able to scale to almost full cluster utilization when scaling up the number of nodes.
Finally, do not underestimate the complexity of data engineering for large-scale training that involves more than language tokens. If your research involves complex or non-standard data types, plan for this engineering overhead early.
Is there anything else you discovered about your experience using Marlowe?
The collaborative support structure was incredibly useful for us. We received cohesive support from Stanford Data Science, Stanford Research Computing, and NVIDIA to help us find solutions for infrastructure-level challenges and squeezing the most performance out of each GPU.
Looking forward, we believe the community would benefit from more extensive documentation on distributed model training and performance engineering, as well as established best practices for complex multimodal data. Better integration of NVIDIA profiling tools and performance monitoring dashboards would also lower the barrier for other research groups pursuing large-scale training on Marlowe.
--
Marlowe is managed and supported by Stanford Data Science, the Vice Provost and Dean of Research, and Stanford Research Computing.
Learn more about the systems managed and supported by Stanford Research Computing.
What to read next:
Navigation Updates for Zoom Web Portal Coming Soon

