Archival Content
a.k.a. “do you really need that PDF about Medicaid billing procedures from 1993?”
Prior to my working for Stanford, I worked as a web developer for a different university medical school. A section of the website that was of great concern for accessibility issues was our alumni magazine, which had issues dating back to the mid 80’s and most of which were scanned PDF files (none were accessible and would take a lot of work to make them so). We discussed many different strategies for fixing these documents, including hiring external companies or bringing on a slew of student workers. That was before I had the idea to check the Google Analytics for the magazine archive page.
In a year's time, there were only 30 page views. While this content seemed important to us (and most of those pageviews were probably our department looking at the pages), the reality was that hardly anyone outside of us cared about this content. And that brings us to an important point:
Part of your accessibility plan should be figuring out what should be deleted rather than fixed.
In the case of the magazine, what we ended up doing was publishing a table of contents for each issue of the magazine with a link to request a copy if someone wanted more. Then, when a request was received, we could deal with the accessibility of the individual requested issue, rather than having to spend a lot of time and money making every issue accessible. In the year or so after making this change, not a single request ever came in for an issue to be sent.
So how do you leverage Siteimprove to help with your determining what documents to keep and what to toss?
First, having the Siteimprove analytics script installed (PM me for info or help) will show you which files are being clicked on from your site (it won’t show you which files are accessed directly from Google or other search engines, however). Look for documents that are never or hardly ever accessed first to decide if you really need it on your site still.
Next, the Siteimprove Inventory tool has a section for documents (QA->Inventory->Documents) which will give you a list of all documents on your site. One of the columns is the “Last Modified” date, which simply looks at the embedded file date and reports what the file reports as the last time it was modified (this date might not be 100% accurate because it may have been modified when the file was simply copied, or other similar factors).
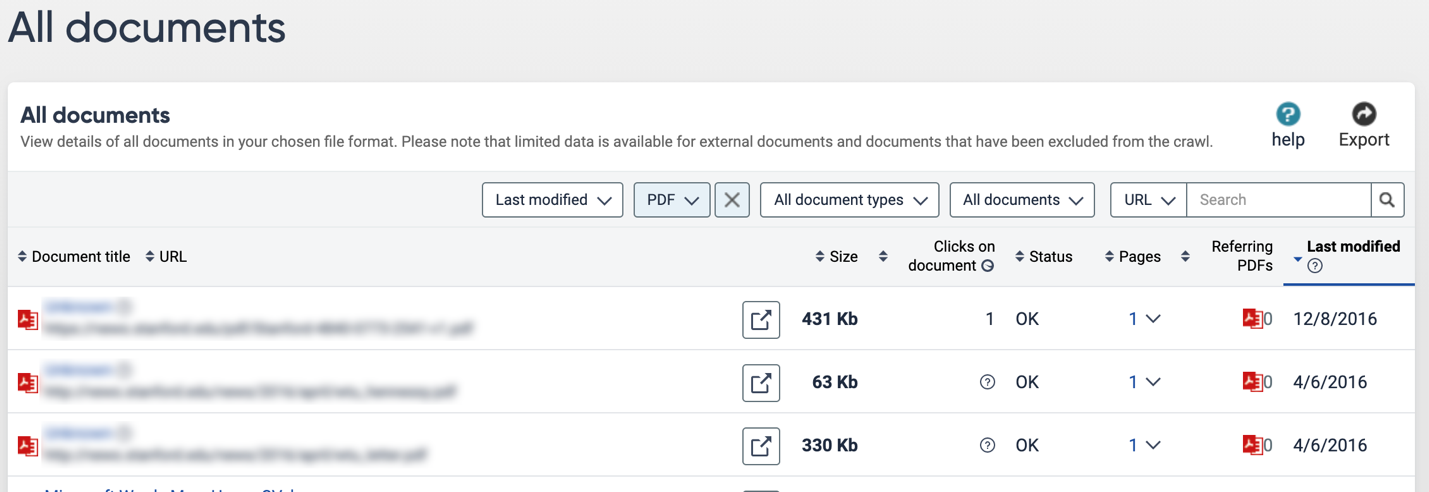
For example, looking at my own department's data, I can see that there are PDF files that date back to 2004. Is this content still relevant and accurate? Now you can start to investigate.
What about pages?
Going past documents such as PDFs though, also think of webpages as something that should be renewed and refreshed, or possibly removed if they are no longer relevant. Again, you can utilize Siteimprove’s inventory section (especially with the analytics script installed) to find all the pages in your site that have very few views, few pages linking to them and a variety of other ways of looking at your content. The Sitemap section is also very useful here for discovering entire directories of content that are old and out of date. We can also create policies that detect pages based on different parameters of your choosing, such as looking for an old name or other factor that would indicate the page’s age.
As always, please let me know if you have any questions or need help with managing your old content.
P.S. And yes, to reference my subject line, in the year 2016 I removed a document from the school of medicine website that was a presentation on Medicaid billing procedures from 1993. It’s no longer the best practice of just throwing any content up on your website because ‘what harm could it cause’. Now that old content is a liability.
DISCLAIMER: UIT Blog is accurate on the publication date. We do not update information in past blog entries. We do make every effort to keep our service information pages up-to-date. Please search our service pages at uit.stanford.edu/search.