Cloud Architecture Principles for IaaS
Summary
This document provides an overview of Cloud Architecture principles and design patterns for system and application deployments at Stanford University. It is meant to be applicable to a range of commodity on-demand computing products in the product category known as IaaS (Infrastructure-as-a-Service). It defines how UIT servers should be built, configured, and operated - whether physical, virtual, or containerized, on campus or in the cloud.
Contents
Principles
The goal of this document is to summarize some of the more important aspects of running IT infrastructure, applications, and related services as cloud deployments. However, while many of these design principles and patterns are not particular to the cloud, and could be applied locally, they become necessary when building reliable cloud services. While it is possible to build cloud-based systems the way we have traditionally, some of our local best practices are in conflict with cloud best practices. For example, PXE-booting new servers (physical or virtual), with manual sysadmin intervention to acquire Kerberos keytabs during the initial install doesn’t work with cloud providers who provide no interactive console access (AWS EC2, for instance). Similarly, sizing a pool of servers to meet peak demand during a few days each year, rather than auto-scaling when needed, is a cloud anti-pattern.
Assume Campus Systems are not Available
A major reason for moving services to the cloud is to increase the fault tolerance of campus IT systems. Our main campus is close to both the San Andreas and Hayward faults. Services running in non-local cloud regions (like Oregon or Ohio) should continue to operate during and after an earthquake. However, any off-campus services (including cloud-based services) or clients that rely on campus-based VPN, authentication, or similar services will stop working.
Servers Are Ephemeral
Historically, servers have been expensive capital investments which were physical assets that were managed with inventory management systems, network registration systems, asset tags, etc. Even on-premise virtual servers used persistent storage which typically would be provisioned from pools of pre-purchased physical storage arrays. Servers are special, and can be repurposed or transferred between groups. When a server dies, it can be rebooted (or repaired, then rebooted). Non-cloud servers have also had fixed, non-reassignable IP addresses, and names in DNS.
Cloud-based servers (aka “instances”) are far more ephemeral; they are started when needed, with random IP addresses and DNS names, and when they are terminated, or die, they are often gone, leaving no trace. Some providers allow the disks attached to instances to be preserved after the instance is terminated, but managing all those redundant volumes creates an additional management burden. Auto-scaled instances are especially ephemeral, since they are automatically launched and terminated based on automated metrics (CPU load, memory availability, network load, etc.).
Servers Are Stateless
Since cloud servers - and their associated local storage - are ephemeral, they should also be stateless. Data must be stored on external storage services; configuration data can be injected at startup, or stored in external data sources.
Always Use Auto Scaling
Due to the ephemeral nature of cloud servers, guaranteeing uptime would be troublesome if cloud providers did not provide autoscaling. While most people think autoscaling is only useful for high-traffic sites, to grow and shrink a pool of servers behind a load-balancer as traffic changes, it can also be used to ensure a minimum number of servers are always running.
For example, a common practice in AWS is to set the minimum and maximum number of servers in an auto-scaling group to 1: if that single server dies, the auto-scaling service will automatically replace it.
Leverage the Features of Our Tools
We often deploy new tools without leveraging the advantages they bring. For example, consider Splunk. Before Splunk was deployed on campus, many UIT groups dumped raw log files to shared file systems, or forwarded logs via syslog/rsyslog to a central logger. After Splunk was deployed, logs continued to be forwarded to Splunk via rsyslog, which require few changes on the log generators, but ignored the capability in the Splunk Forwarder for parsing specific log files into structured data.
Always Use Custom Images
If the auto-scaling service is automatically replacing servers as needed, with what does it replace them? While different providers have different names for their auto-scaling service and definitions, most support using a pre-created image to bootstrap new servers (AWS calls them launch configurations and Amazon Machine Images (AMIs); Google calls them instance groups and instance templates). Custom images should be as close to MinSec compliant (for the MinSec level required by the application) as is possible.
While it's possible to use a base image then configure it with tools like Puppet after it boots, the accepted approach is to build unique images for each service. Those images require little to no configuration when started, so minimize the outage window (for single instance groups), or the time it takes to handle a traffic increase (for multi-instance groups). Any additional configuration should be imported or created using cloud-init, mounted from external storage, or injected via the environment.
Images should be built using automated provisioning and configuration management tools. Systems running from images should not be patched; instead, a new image should be build and the running systems replaced with ones running the new image.
Similarly, configuration files should be built using automated configuration management tools, and stored in storage systems that are secure, but easily attached to systems at boot time.
New images and configurations should be tested, preferably using automated tests, before being deployed.
Credentials should not be stored in images, nor should they be stored in automatically generated configuration files. Credentials should be stored securely and made available to systems at boot time.
For example, the images for the new SAML IdPs are built by a continuous integration job running on a Jenkins server. The images are built from a base image and a Puppet manifest, and contain only very generic configuration. The real configuration is generated by another Jenkins job using a Puppet manifest, then pushed by Jenkins into a shared file-system that is available on the IdPs.
Build Loosely Coupled Services
When the number of servers in a load-balanced pool can vary from hour to hour, or the IP address of a single-instance service can change from day to day, services must be loosely coupled. External-facing services should be load-balanced; back-end databases should be clustered (or use a highly-available database service like AWS' Relational Database Service (RDS); any middleware or application server tiers should also be load-balanced.
Nothing should rely on specific IP addresses. In practice, this means using static DNS names and public IPs for all services. Clients, including other services, must connect to services using DNS names (which must resolve to public IPs). All service-to-service and all non-public client-to-service connections must require strong authentication (using OAuth 2.0, client certificates, or GSSAPI / Kerberos), and data sent across those connections must be encrypted (i.e., HTTPS, other TLS-based protocol, or GSSAPI / Kerberos).
Cloud providers have features to segregate groups of instances and control traffic between those groups (AWS uses security groups as both a grouping mechanism and an access control mechanism; Google uses subnetworks and firewalls). Hosts within the same subnet or security group should also be protected from each other, unless the application configuration specifically requires otherwise.
Hybrid Architectures Should Also Be Loosely Coupled
If you have a hybrid architecture, with some services running in one cloud, and other services running in a separate cloud, or on servers on campus, you should still ensure that they are loosely coupled.
Historically, many campus-based services have used “private” IPs from the RFC1918 non-routable address spaces, assuming that this is more secure. In practice, those services are all behind firewalls, so could use public IPs without any additional risk. Additionally, the small security benefit provided is far outweighed by the decreased accessibility from off-campus clients and services.
Servers behind load balancers can still use private IPs, but the front-end (public-facing) load balancer must have a public IP. Servers that will never be accessed outside their local environment can also use private IPs.
No Patching or Updates on Running (Virtual) Systems
Physical servers must be patched according to MinSec requirements. Since virtual servers (VMware or Hyper-V VMs, AWS EC2 instances, Docker Containers, etc.) should have no local state, they should be replaced with instances running a newer version of the image. If application patching also patches the database, it’s preferable to split the application and database patching into separate processes. If the patching cannot be separated, or the patches are not backwards-compatible (i.e. the new application version cannot use the old database version, or vice-versa), then the service will have to be stopped while a patched image is built and used to patch the database. Obviously, this is not ideal, and should be addressed with the application vendor.
Cost Optimization (and Control)
Only provision the amount of resource your application requires at a given time. Only over-provision when start up time is greater than your service will tolerate. Ensure that your architecture uses auto-scaling wherever possible to ensure only the minimum required number of instances are running, based on application / service load or responsiveness.
Cloud providers often provide alerting facilities for when the monthly bill exceeds a threshold; configure alerts for your cloud accounts with appropriate thresholds, and with notifications going to mailing lists.
Design Systems for Fault-Tolerance
Reboot and machine failure are considered normal. The services should be designed to handle reboot caused by system patching, self-upgrade, machine replacement etc. By designing to account for subsystem failure, the service associated with the failure will not be affected - that is, the design is fault-tolerant.
Secure Bastion Hosts
Secure bastion hosts should enforce multi-factor authentication (e.g. SSH key and Duo, or Kerberos and Duo), or only allow access via physically secured credentials (e.g. SSH keys generated on a PIN- and touch- protected Yubikey). While bastion hosts must be used to access other servers within the protected network, those hosts must not store credentials for access to servers. Bastion hosts using SSH keys should not allow users to upload additional trusted keys; only keys installed by configuration management should be trusted.
Architectures
The following are common design models of deployments of applications and other services. Much of the basic concepts of tiered segmentation and scalability are consistent when moving to IaaS cloud deployments. For completeness, this document does reference those classic models but emphasises what changes when moving to the cloud, in order to prioritize any refactor or redesign efforts needed for migrating services.
What Stays the Same in the Cloud?
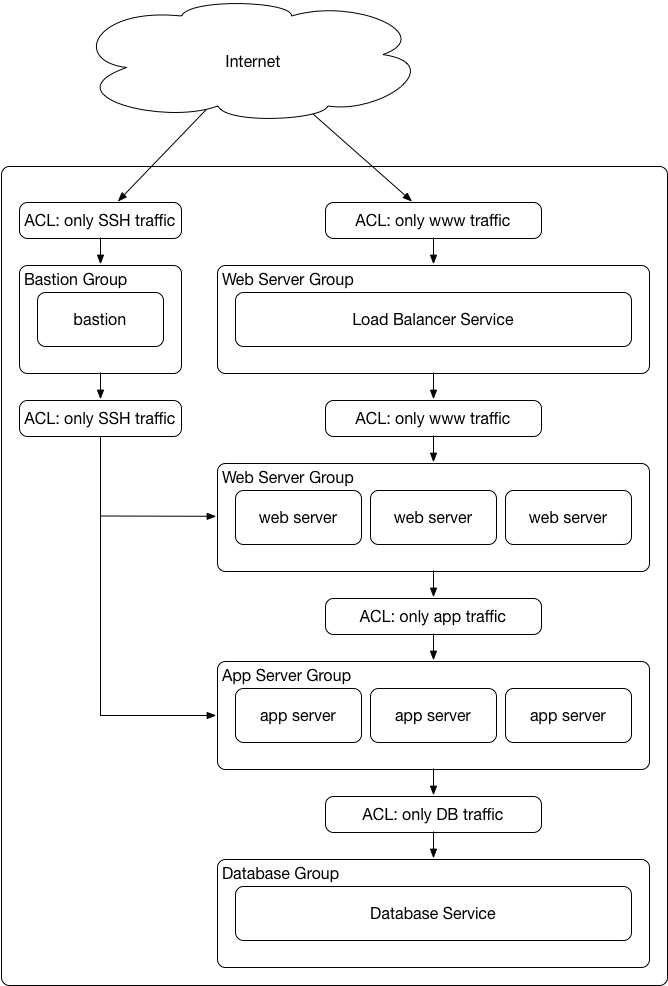
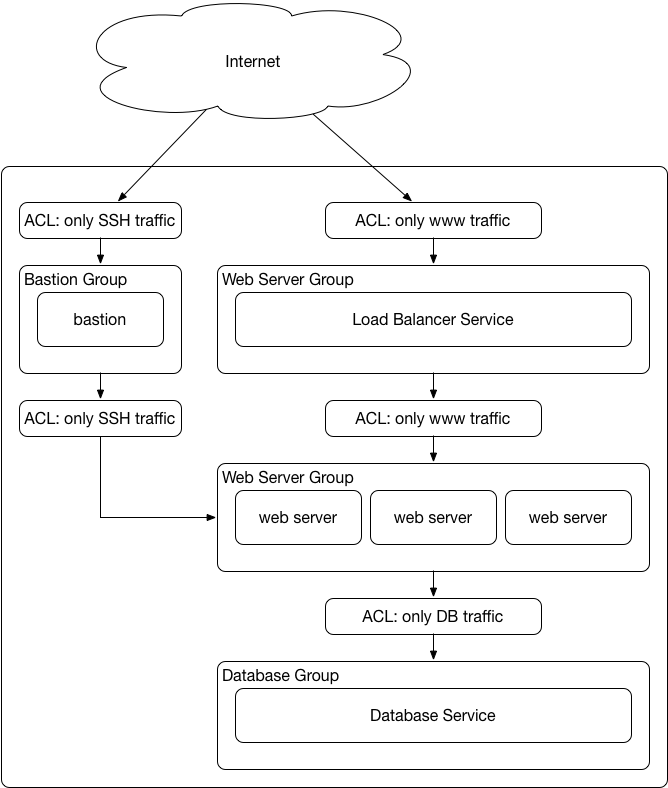
In many ways, cloud deployments retain many of the standard elements of multi-tiered application architectures. For example, there is still often a motivation to segment the display layer from application execution in order to scale each independently. It is still important to secure the network connections between the tiers or subsystem elements of an application in order to isolate any compromised hosts.
What Changes in the Cloud?
There are several changes we make when we design or refactor an application for cloud deployment:
Access control inherent in IaaS service - IaaS provider platforms include network access controls that provide segmentation between applications, and application tiers, that is normally provided by firewalls.
Secure bastion hosts should be used rather than allowing administrative access to servers from trusted networks, which requires either public IPs and inbound firewall rules for every server / security group / subnet, or requires VPN endpoints inside every IaaS account / network / VPC. Each application should be in a separate account, or separate “virtual cloud” within an account. Each application should have a dedicated secure bastion host; bastion hosts should not be shared between applications.
Bastion host security is covered in Operational Principles and Practices for all UIT Servers.
Generic 3 Tier Architecture
Generic 2 Tier Architecture
Generic Single Instance Architecture
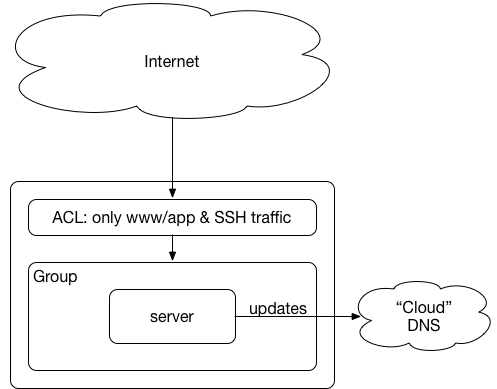
For single instance setups, delegate the specific domain from stanford.edu DNS to the cloud DNS, then use APIs to update the cloud DNS. [See cpauth.stanford.edu and who.stanford.edu for examples].
Example Architectures
- Single instance - who.stanford.edu or cpauth.stanford.edu (without automation)
- Homepage - master server to build image, autoscaled cluster